|
Jiahao Zhan 「詹佳豪」 I am a Ph.D. student at CUHK MMLab starting from Fall 2026, advised by Tianfan Xue. I am supported by the Hong Kong PhD Fellowship. I obtained my B.E. in Artificial Intelligence from the College of Computer Science and Artificial Intelligence at Fudan University in 2026. My undergraduate thesis was supervised by Xipeng Qiu and Xinchi Chen. Before starting PhD, I had the pleasure of collaborating with Dequan Wang at Shanghai Jiao Tong University, Hang Zhao at Tsinghua University, Qifeng Chen at HKUST, and Jiajun Wu at Stanford University. |

👋 Hover over the photo |
ResearchI am interested in how AIGC can create more compelling user experiences and be applied to real-world applications. Some papers are highlighted. |

|
PerpetualWonder: Long-Horizon Action-Conditioned 4D Scene Generation
Jiahao Zhan*, Zizhang Li*, Hong-Xing Yu, Jiajun Wu CVPR, 2026, Highlight project page / arXiv / github A hybrid generative simulator enabling long-horizon, action-conditioned 4D scene generation from a single image via a unified representation that links physical state and visual primitives. |
|
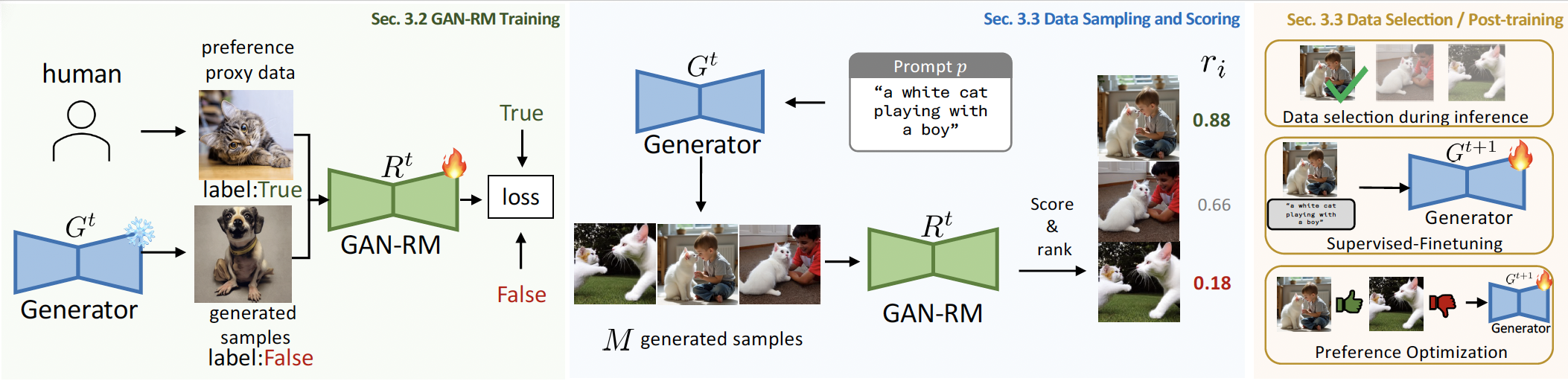
DisRM: Reward Modeling as Discriminative Prediction
Runtao Liu*, Jiahao Zhan*, Yuxuan GUO, Yingqing He, Chen Wei, Alan Yuille, Qifeng Chen ECCV, 2026 arXiv / github An efficient reward modeling framework inspired by GANs that eliminates manual preference annotation, training through discrimination between target samples and model-generated outputs. |
|
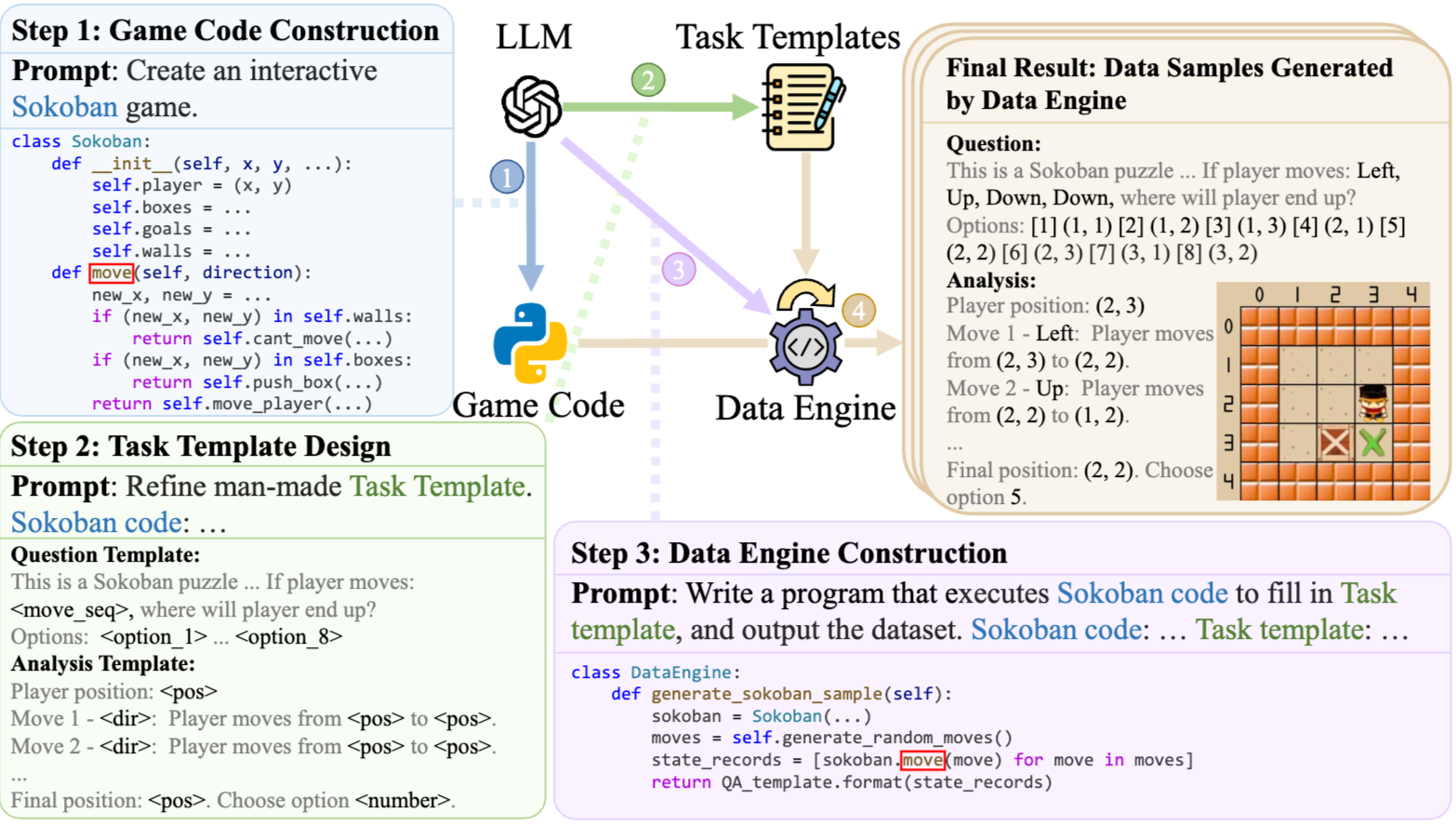
Game-RL: Synthesizing Multimodal Verifiable Game Data to Boost VLMs' General Reasoning
Jingqi Tong, Jixin Tang, Hangcheng Li, Yurong Mou, Ming Zhang, Jun Zhao, Yanbo Wen, Fan Song, Jiahao Zhan, Yuyang Lu, Chaoran Tao, Zhiyuan Guo, Jizhou Yu, Tianhao Cheng, Zhiheng Xi, Changhao Jiang, Zhangyue Yin, Yining Zheng, Weifeng Ge, Guanhua Chen, Tao Gui, Xipeng Qiu, Qi Zhang, Xuanjing Huang ICLR, 2026 project page / arXiv / github A reinforcement learning framework that synthesizes verifiable multimodal game tasks from game code, enabling VLMs trained on GameQA to improve general reasoning across diverse vision-language benchmarks. |
|
Generalizing Motion Planners with Mixture of Experts for Autonomous Driving
Qiao Sun*, Huimin Wang*, Jiahao Zhan, Fan Nie, Xin Wen, Leimeng Xu, Kun Zhan, Peng Jia, Xianpeng Lang, Hang Zhao ICRA, 2025 project page / arXiv / github A scalable motion planner using ViT encoder and MoE causal Transformer that generalizes better across different driving scenarios. |

|
MAC: A Live Benchmark for Multimodal Large Language Models in Scientific Understanding
Mohan Jiang, Jin Gao, Jiahao Zhan, Dequan Wang COLM, 2025 arXiv A live benchmark leveraging 25,000+ image-text pairs from top-tier journals to evaluate MLLMs' cross-modal scientific reasoning. |
Research Experiences |
|
|
Bytedance MMlab Nov. 2025 - Present Algorithm Engineer Intern, mentored by Qunliang Xing and Shijie Zhao |

|
Stanford Vision and Learning Lab Jun. 2025 - Nov. 2025 Research Intern (UGVI), advised by Prof. Jiajun Wu |

|
HKUST Visual Intelligence Lab Jan. 2025 - Jun. 2025 Research Intern, advised by Prof. Qifeng Chen |

|
Shanghai Qi Zhi Institute May. 2024 - Jan. 2025 Research Intern, advised by Prof. Hang Zhao |

|
Shanghai AI Lab Mar. 2023 - May. 2024 Research Intern, advised by Prof. Dequan Wang |
Services |
|
• ECCV 2026 Reviewer |
Honors |
|
• Hong Kong PhD Fellowship, 2026 - 2030 • CUHK Vice-Chancellor Scholarship, 2026 • National Scholarship, 2023, 2024 • Shanghai Outstanding Graduate • Third Prize, Shape Completion and Reconstruction of Sweet Peppers Challenge (ECCV Workshop) • Second Prize, Intel LLM-based Application Innovation Contest (Team Leader) |
|
Website template from Jon Barron. |