
| CV |
Email |
Google Scholar |
|
I am a senior student at Fudan University, majoring in Artificial Intelligence. I love to explore the world and learn new things, eg., traveling, reading, and coding. For my research, I focus on building applicable intelligence systems, leveraging the knowledge from powerful generative models to solve real-world problems. Specifically, I have a lot of experience in interactive 3D scene generation and visual alignment. Email: 22307140116 [AT] m.fudan.edu.cn If you are interested in my experience, please feel free to contact me. My WeChat: zjh1802664220 |
|
abstract |
bibtex |
arXiv
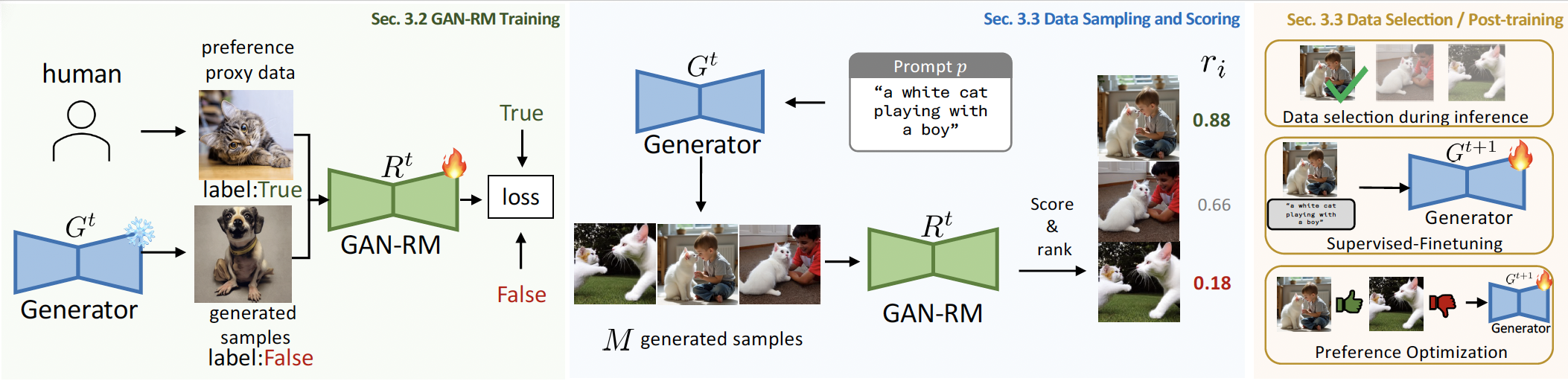
An effective reward model plays a pivotal role in reinforcement learning for post-training enhancement of visual generative models. However, current approaches of reward modeling suffer from implementation complexity due to their reliance on extensive human-annotated preference data or meticulously engineered quality dimensions that are often incomplete and engineering-intensive. Inspired by adversarial training in generative adversarial networks (GANs), this paper proposes GAN-RM, an efficient reward modeling framework that eliminates manual preference annotation and explicit quality dimension engineering. Our method trains the reward model through discrimination between a small set of representative, unpaired target samples(denoted as Preference Proxy Data) and model-generated ordinary outputs, requiring only a few hundred target samples. Comprehensive experiments demonstrate our GAN-RM's effectiveness across multiple key applications including test-time scaling implemented as Best-of-N sample filtering, post-training approaches like Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO).
@misc{liu2025faketillmakeit,
title={Fake it till You Make it: Reward Modeling as Discriminative Prediction},
author={Runtao Liu and Jiahao Zhan and Yingqing He and Chen Wei and Alan Yuille and Qifeng Chen},
year={2025},
eprint={2506.13846},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2506.13846},
}
|
|
webpage |
pdf |
abstract |
bibtex |
arXiv
Large real-world driving datasets have sparked significant research into various aspects of data-driven motion planners for autonomous driving. These include data augmentation, model architecture, reward design, training strategies, and planner pipelines. These planners promise better generalizations on complicated and few-shot cases than previous methods. However, experiment results show that many of these approaches produce limited generalization abilities in planning performance due to overly complex designs or training paradigms. In this paper, we review and benchmark previous methods focusing on generalizations. The experimental results indicate that as models are appropriately scaled, many design elements become redundant. We introduce StateTransformer-2 (STR2), a scalable, decoder-only motion planner that uses a Vision Transformer (ViT) encoder and a mixture-of-experts (MoE) causal Transformer architecture. The MoE backbone addresses modality collapse and reward balancing by expert routing during training. Extensive experiments on the NuPlan dataset show that our method generalizes better than previous approaches across different test sets and closed-loop simulations. Furthermore, we assess its scalability on billions of real-world urban driving scenarios, demonstrating consistent accuracy improvements as both data and model size grow.
@misc{sun2024generalizingmotionplannersmixture,
title={Generalizing Motion Planners with Mixture of Experts for Autonomous Driving},
author={Qiao Sun and Huimin Wang and Jiahao Zhan and Fan Nie and Xin Wen and Leimeng Xu and Kun Zhan and Peng Jia and Xianpeng Lang and Hang Zhao},
year={2024},
eprint={2410.15774},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2410.15774},
}
|

|
abstract |
bibtex |
arXiv
As multimodal large language models (MLLMs) grow increasingly capable, fixed benchmarks are gradually losing their effectiveness in evaluating high-level scientific understanding. In this paper, we introduce the Multimodal Academic Cover benchmark (MAC), a live benchmark that could continuously evolve with scientific advancement and model progress. MAC leverages over 25,000 image-text pairs sourced from issues of top-tier scientific journals such as Nature, Science, and Cell, challenging MLLMs to reason across abstract visual and textual scientific content. Experiments on our most recent yearly snapshot, MAC-2025, reveal that while MLLMs demonstrate strong perceptual abilities, their cross-modal scientific reasoning remains limited. To bridge this gap, we propose DAD, a lightweight inference-time approach that enhances MLLMs by extending MLLM visual features with language space reasoning, achieving performance improvements of up to 11%. Finally, we highlight the live nature of MAC through experiments on updating journal covers and models for curation, illustrating its potential to remain aligned with the frontier of human knowledge.
to be released
|

|
The Third Prize |

|
Press conference
The Second Prize |
|
|
Bytedance MMlab |

|
Stanford Vision and Learning Lab |

|
HKUST Visual Intelligence Lab |

|
Shanghai Qi Zhi Institute |

|
Shanghai AI Lab |
|
|